
Lesson 1: Full Stack Development & Node.js
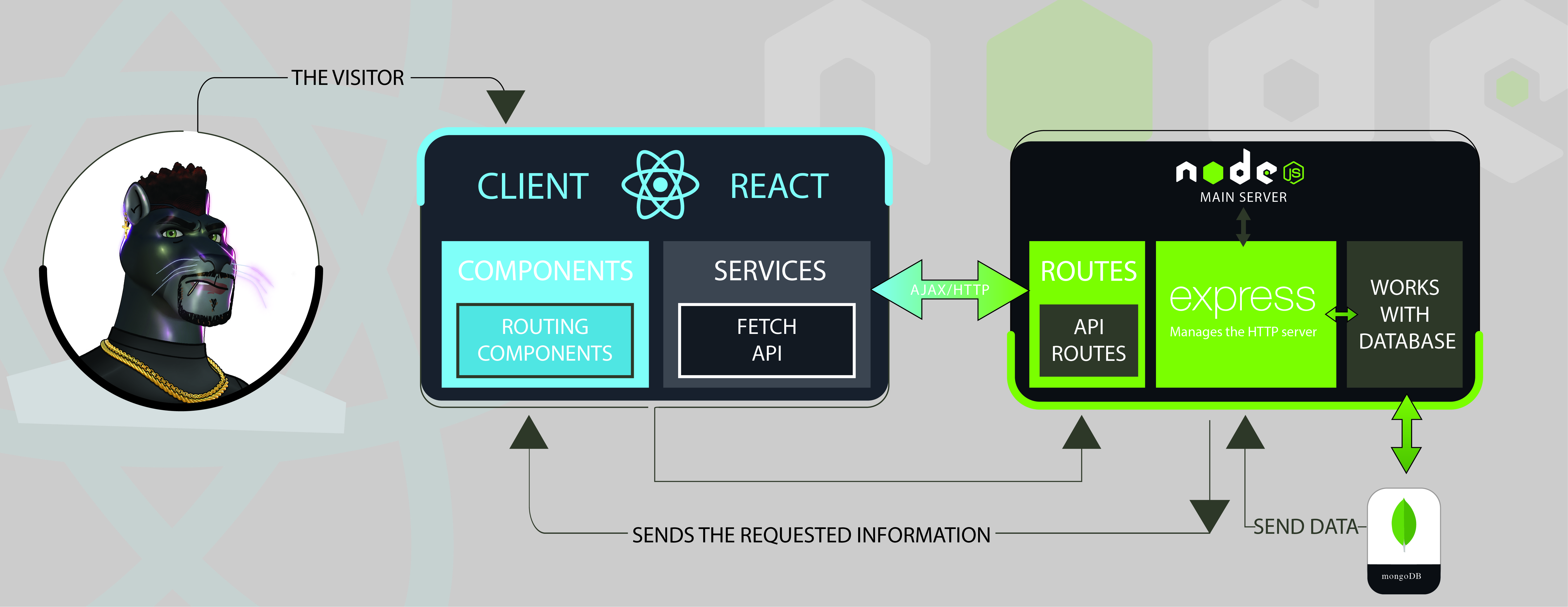
Objectives:
- Explain Full-Stack Web Development
- Describe Client/Server Architecture
- Explain the Anatomy of HTTP Requests and Responses
- Identify the Two Key Components of an HTTP Request
- Explain How HTTP Requests Can be Initiated From a Browser
Explanation
Full-stack web development is the process of building both the front-end (client-side) and back-end (server-side) parts of a web application. The front-end is what the users interact with, while the back-end manages data processing, storage, and communication between the front-end and any databases or other services.
The client-server architecture is a foundational concept in full-stack development. In this architecture, the client (usually a web browser) sends requests to a server, which processes the requests and sends back the appropriate response. The communication between the client and server typically happens via the Hypertext Transfer Protocol (HTTP).
Introduction to Full Stack Development
Full Stack Development refers to the process of developing both the frontend (client-side) and backend (server-side) of a web application. As a Full Stack Developer, you'll be responsible for creating the user interface, handling user input, managing data storage, and processing data on the server.
Introduction to Node.js
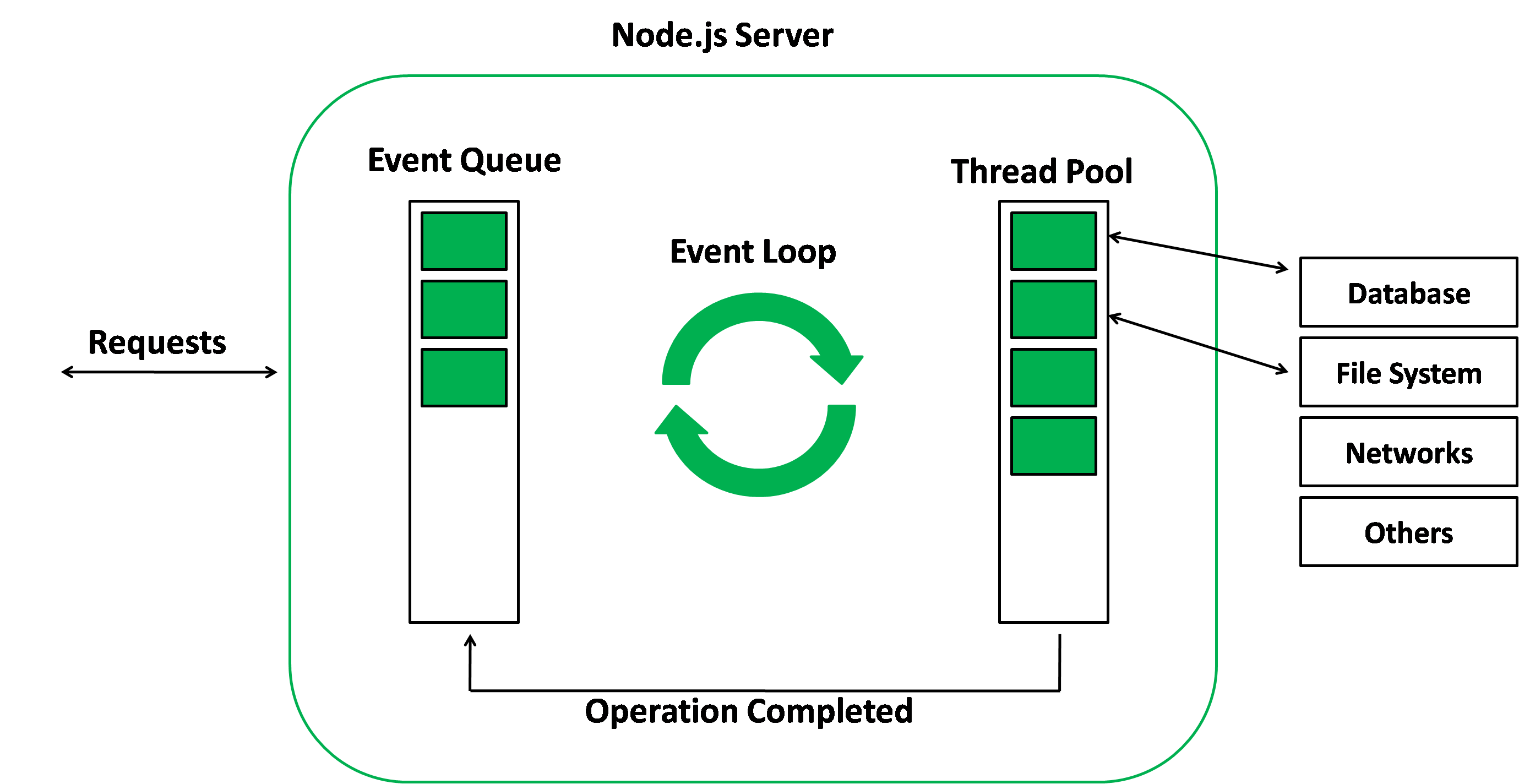
Node.js is an open-source, cross-platform runtime environment that allows you to run JavaScript on the server-side. It's built on the V8 JavaScript engine, the same engine that powers Google Chrome. Node.js uses an event-driven, non-blocking I/O model, which makes it efficient and lightweight.
Node.js is performant for several reasons, which primarily stem from its design principles and the technology it's built on. Here are some key factors that contribute to Node.js's performance:
- V8 JavaScript Engine: Node.js is built on the V8 JavaScript engine, developed by Google for Chrome. V8 is designed for high performance and is constantly optimized by Google. It compiles JavaScript directly into machine code, which allows Node.js applications to run at near-native speeds.
- Event-driven, non-blocking I/O: Node.js uses an event-driven architecture, meaning it can handle multiple tasks concurrently without waiting for a task to complete before starting another. This is particularly beneficial when dealing with I/O-bound operations, such as reading from or writing to a file, making database queries, or handling network requests. In a traditional blocking I/O model, the application would wait for each operation to finish before moving on to the next one, which could lead to performance bottlenecks. Node.js's non-blocking I/O model ensures that it can efficiently manage multiple tasks at the same time, resulting in better overall performance.
- Single-threaded with asynchronous processing: While Node.js runs on a single thread, it makes use of asynchronous processing through the event loop. This allows it to handle multiple tasks without the need for multi-threading and the associated overhead. The event loop continually checks for new tasks, processes them, and queues their callbacks for execution. This results in a lightweight and efficient process that can handle many requests simultaneously without the need for thread context switching.
- Scalability: Node.js is designed to be scalable, allowing developers to build applications that can handle a large number of simultaneous connections with ease. This is particularly useful for building high-performance APIs, real-time applications, and data-intensive applications that require efficient handling of multiple requests.
In summary, Node.js's performance can be attributed to its use of the V8 JavaScript engine, event-driven and non-blocking I/O model, single-threaded and asynchronous processing, and scalability. These factors allow Node.js to efficiently manage multiple tasks concurrently and provide a fast and responsive server-side platform for building web applications.
Client-Server Model Analogy
Imagine a restaurant. The customers (clients) come to the restaurant to order food. The kitchen (server) is where the food is prepared and cooked. The waiter (communication protocol) takes the orders (requests) from the customers, delivers them to the kitchen, and brings the prepared dishes (responses) back to the customers.
In this analogy, the customers represent web browsers or other applications that interact with a server. The kitchen represents the server-side infrastructure that processes requests and delivers the required information or resources. The waiter represents the communication protocol (e.g., HTTP) that facilitates the exchange of information between the client and the server.
Node.js Analogy
Think of a library. In the library, there's a librarian (Node.js) who can efficiently manage multiple requests from library visitors (clients) simultaneously. The librarian can handle requests such as searching for books, checking them out, and returning them, all without making the visitors wait in a long line.
In this analogy, the librarian represents Node.js, which is responsible for managing multiple client requests concurrently. The library visitors represent clients who interact with a server-side application built on Node.js. The efficiency of the librarian is analogous to Node.js's event-driven, non-blocking I/O model, which allows it to manage multiple tasks simultaneously without waiting for one task to complete before starting another.
Important Concepts in Full Stack Development
- CRUD: CRUD stands for Create, Read, Update, and Delete. These are the four basic operations that can be performed on any data resource in a web application. CRUD operations are essential in most applications because they provide the necessary functionality to manage data. For instance, users can create new records, read existing records, update records with new information, or delete records that are no longer needed. CRUD is best modeled by a to-do list. You can Create a new task, Read the tasks you already have, Update a task you've already created, and Delete a task you no longer need. It's a basic set of operations that allows you to manage data in a database.
- REST: REST (Representational State Transfer) is an architectural style for designing networked applications. It provides a set of constraints and principles that guide developers to build scalable and maintainable APIs. RESTful APIs use standard HTTP methods (GET, POST, PUT, DELETE) to perform CRUD operations on resources, which are identified by URIs (Uniform Resource Identifiers). REST encourages statelessness, meaning the server should not store any information about the client's state between requests. This makes RESTful APIs easier to scale and maintain. REST is like a menu at a restaurant. Just like how a menu lists different dishes available at the restaurant, REST defines different endpoints (or "dishes") that are available in a web service. Each endpoint represents a specific resource that can be accessed and manipulated using standard HTTP methods (GET, POST, PUT, DELETE).
- Server-Side Rendering (SSR): In Server-Side Rendering, the server generates the complete HTML content for a web page and sends it to the client's browser, which then renders the page. With SSR, the server is responsible for processing the data and generating the final HTML, CSS, and JavaScript needed to display the page. This means that the client's browser receives a fully-rendered page, and there's less work for it to do before displaying the content to the user. SSR can provide benefits such as improved SEO, faster initial page load times, and better support for older browsers. Server-side rendering is like a chef preparing a dish in the kitchen before bringing it out to the customers. The chef (server) prepares the dish (HTML) and then serves it to the customer (browser) who requested it. With server-side rendering, the server generates the HTML for a web page and sends it to the browser, as opposed to the browser generating the HTML.
- Client-Side Rendering (CSR): In Client-Side Rendering, the initial HTML sent by the server contains a minimal structure, and the browser is responsible for generating the final HTML, CSS, and JavaScript needed to display the page. This is often done using JavaScript frameworks like React, Angular, or Vue.js. With CSR, the client's browser does most of the work, such as fetching data from APIs, rendering components, and updating the DOM. CSR can provide benefits such as faster subsequent page loads, a more interactive user experience, and easier development using modern JavaScript frameworks.Client-side rendering is like a customer ordering a dish at a restaurant and then being able to customize it themselves. The customer (browser) receives the basic ingredients (data) and then prepares the dish (HTML) to their liking. With client-side rendering, the browser receives the data and generates the HTML, as opposed to the server generating the HTML.
In summary, CRUD operations are the fundamental actions for managing data in web applications, REST is an architectural style that simplifies building scalable APIs, Server-Side Rendering generates complete HTML pages on the server before sending them to the browser, and Client-Side Rendering delegates most of the rendering work to the client's browser. Each of these concepts plays a crucial role in the development of modern web applications.
Demonstration
Anatomy of HTTP Requests and Responses
An HTTP request has two main components: the request line and the request header. The request line specifies the HTTP method (e.g., GET, POST, PUT, DELETE), the target URL, and the HTTP version. The request header contains additional information such as the user agent, content type, and any cookies.
An HTTP response has three main components: the status line, the response header, and the response body. The status line contains the HTTP version, the status code, and a status message. The response header provides additional information such as the server type, content type, and caching directives. The response body contains the actual content, which can be HTML, JSON, images, or any other type of data.
Initiating HTTP Requests from a Browser
When a user enters a URL in the browser's address bar, clicks a link, or submits a form, the browser initiates an HTTP request to the server. Depending on the action, the browser may send a GET, POST, PUT, or DELETE request to the server, which then processes the request and sends back the appropriate response.
Imitation
During this lesson, we will imitate the process of creating an HTTP request and receiving an HTTP response using a simple web application. You will see how the browser sends an HTTP request to a server, and how the server processes the request and sends back an HTTP response with the requested data.
Practice
Part 1
To practice the concepts learned in this lesson, you will complete the following activities:
- Use an online HTTP request tool (such as Postman) to create and send HTTP requests to a sample web server. Experiment with different HTTP methods, request headers, and request bodies.
- Analyze the HTTP response received from the server. Identify the status line, response header, and response body.
- Explore how changing different parts of the request (e.g., HTTP method, URL, request headers) affects the response received from the server.
Part 2
Setting up a Node.js development environment
- To install Node.js, visit the official Node.js website and download the installer for your operating system. Follow the installation instructions provided.
- Once installed, open your terminal or command prompt, and type
node -vto check the installed version of Node.js. You should see the version number as output. - Similarly, type
npm -vto check the installed version of the Node Package Manager (NPM). NPM is included with Node.js and is used to manage packages and dependencies.
NPM and package.json
- Create a new directory for your project and navigate to it in your terminal or command prompt:
mkdir my-node-app
cd my-node-app- To initialize your project and create a
package.jsonfile, type:
npm init -yThis command creates a package.json file with default values. The package.json file is used to store metadata about your project, like the name, version, and dependencies.
Creating a basic Node.js application
- In your project directory, create a new file called
index.js:
touch index.js- Open the
index.jsfile in your favorite text editor and add the following code:
const http = require('http');
const hostname = '127.0.0.1';
const port = 3000;
const server = http.createServer((req, res) => {
res.statusCode = 200;
res.setHeader('Content-Type', 'text/plain');
res.end('Hello World!\n');
});
server.listen(port, hostname, () => {
console.log(`Server running at http://${hostname}:${port}/`);
});This code creates a simple HTTP server that listens on port 3000 and responds with "Hello World!" to every request.
- Save the file and go back to your terminal or command prompt. Run the following command to start your Node.js application:
node index.js- Open your web browser and navigate to
http://127.0.0.1:3000. You should see the "Hello World!" message displayed.
Congratulations! You've just created a basic Node.js application. This is just the beginning of what you can achieve with Node.js and Full Stack Development. As you progress through your course, you'll learn more about creating complex applications, managing data, and connecting to frontend frameworks.